REPRESENTATION D'UN TEXTE EN MACHINE
EXERCICE 1: ASCII
Question 1.1
En utilisant la table de codage ASCII ( fig1 du chapitre Ressources), décoder le mot suivant: 4E 53 49
Question 1.2
En utilisant la table de codage ASCII ( fig1 du chapitre Ressources),
1.2.1 coder votre nom en utilisant la représentation hexadécimale du code ASCII des caractères de votre nom ( selon les caractères de votre nom ce ne sera complètement possible, il vous faudra remplacer les caractères accentués par un caractère similaire sans accent: é devient e par exemple)
1.2.2 De combien de bits votre nom est composé en ASCII? De combien d'octets votre nom est composé ?
EXERCICE 2: messages secrets
On pourrait imaginer rendre secret un message en le codant en ASCII, malheureusement vous avez vu qu'avec une table ASCII on retrouve facilement le message. Les équipements numériques qui échangent des messages comme les textos n'envoient pas les bits avec la valeur ASCII des caractères; pour les communications entre appareils numériques, les échanges sont chiffrés. Il existe plusieurs algorithmes de chiffrement que vous découvrirez en NSI.
Information: On appelle codage quand on représente des caractères avec des nombres numériques donnés dans une table publique (connue de tous les informaticiens comme la table ASCII). On appelle chiffrer quand on représente des caractères dans le but de les rendre incompréhensibles pour qui n'a pas la clé de déchiffrement. Vous rencontrerez parfois le terme crypter un message mais c'est un abus de langage qui vient de l'Anglais encrypt qui veut dire chiffrer.
On vous propose dans cet exercice de chiffrer un message avec le code de César. Cette méthode de chiffrement, très simple, était utilisée par L'empereur Romain Jules César dans ses correspondances secrètes ce qui a donné le nom de « code de César ». Le texte chiffré s'obtient en remplaçant chaque lettre du texte original par une autre lettre , à distance fixe et toujours du même côté, de l'alphabet. Par exemple avec un décalage de 8 caractères vers la droite dans l'alphabet (voir la roue codeuse ci-dessous fig4) , A est remplacé par I, B devient J , et ainsi de suite jusqu'à Z qui devient H.
La longueur du décalage 8 caractères vers la droite est appelée la clé du chiffrement, il suffit de la transmettre au destinataire pour qu'il puisse déchiffrer. La roue photographiée ci-dessous fig4, vous montre en jaune le "vrai" caractère d'un texte chiffré qui affiche les caractères de la zone orange ( la clé est ici 8):
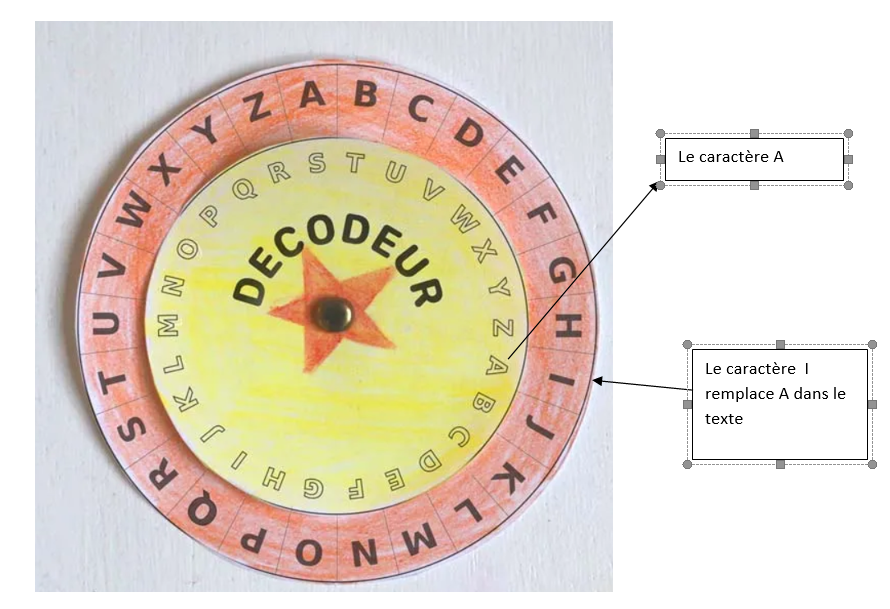
fig4
On a utilisé une clé de 8 pour chiffrer un message et obtenu le texte suivant:
ZWCKWCTM UI TWCBM
Question 2.1
Décoder le message chiffré en vous aidant de la roue photographiée fig 4
Question 2.2
Chiffrer votre prénom avec une clé de 6. Pour ça il vous faut créer une roue avec un décalage de 6 ce qui met le A ( de la roue jaune) en face du caractère de la roue rouge situé 6 caractères après le A. télécharger le fichier de la roue ci-joint puis utiliser le tuto de la vidéo ci-jointe pour modifier l'image.
{kind=link}
Question 2.3
Les limites du code de César:
Il n'y a pas besoin d'être un expert en déchiffrement pour casser le code de César. Si on connaît la langue d'origine du texte chiffré on peut se baser sur les lettres les plus fréquentes de cette langue pour découvrir la clé.
En français, le caractère le plus fréquent est le "e", il suffit de se dire que le caractère le plus fréquent du texte chiffré est en réalité un "e" pour deviner la clé. Ci-dessous , le caractère le plus fréquent du message chiffré est "g" , on se dit que le "g" est en réalité un "e" ce qui correspond à un décalage de 2 caractères (une clé de 2 ) ce qui nous permet de déchiffrer le message:
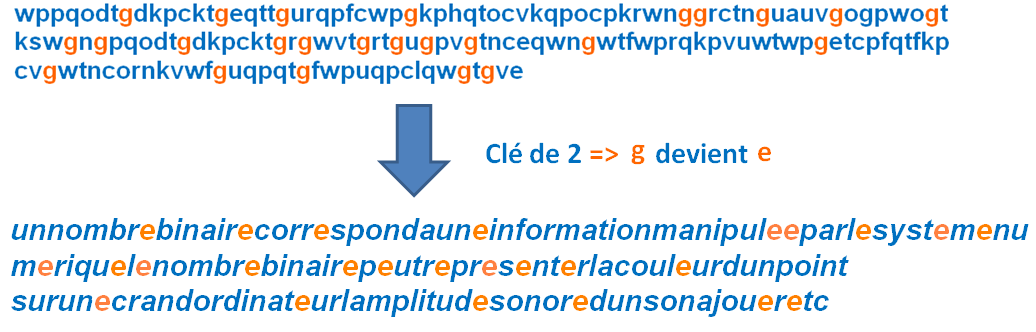
Cependant ce n'est pas toujours aussi simple selon la nature du texte les lettres fréquentes peuvent être différentes. Si le texte chiffré est court cette méthode ne fonctionne pas bien, s'il est long elle donne de bons résultats. Un programme informatique qui teste toute les clés mettra moins d'une seconde pour casser le code de César.
On vous donne le message chiffré ci-dessous:
mbtbvdjttftfdifefmbsdijevdifttfftufmmftfdif
2.3.1 quelle est la lettre la plus fréquente?
2.3.2 quelle est la clé de chiffrement si cette lettre la plus fréquente est en réalité un "e" ?
2.3.3 que devient la partie du message suivante mb tbvdjttf tfdif si vous la déchiffrez avec votre clé?
EXERCICE 3 : ISO-latin1
Question 3.1
Coder avec la représentation hexadécimale du codage de la table ISO-latin1, chaque caractère du mot NSI, comparer avec la version ASCII de ce mot.
Question 3.2
Coder avec la représentation binaire du codage de la table ISO-latin1, chaque caractère du mot NSI .
EXERCICE 4 : UTF-8
Voir le chapitre Ressources pour un rappel du principe de codage en utf-8
Question 4.1
Le code UTF-8 est-il compatible avec le codage ISO-LATIN1? Justifier votre réponse en comparant le codage de é dans les deux codes.
Questions 4.2
Vous utilisez probablement des émoticônes dans vos textos, sachez que ce sont des caractères UCS comme les autres, ils ont une version UTF-8.
Le site https://unicode.org/emoji/charts/emoji-list.html vous donne l'ensemble des émoticônes et leur point de code. Voici un extrait de la table des émoticônes, la colonne Code donne la valeur UCS, en utilisant son point de code:

fig 8
4.2.1 Donner le point de code du caractère appelé grinning face.
4.2.2 Convertir en binaire et en décimal le point de code du caractère grinning face.
4.2.3 Déduire le format UTF-8 du caractère avec le tableau ci-dessous ( fig6)

4.2.4 Déduire en utilisant vos résultats précédents le code UTF-8 du caractère grinning face.
EXERCICE 5: format et taille de fichier
Question 5.1
Quelle est l'influence du codage choisi ( ASCII, UTF-8, etc..) sur la taille d'un fichier texte? Pour répondre à cette question, on vous propose deux fichiers à télécharger cigale_utf et cigale-iso qui contiennent la même texte à analyser:
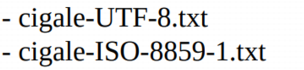
Donner la taille des fichiers. Quel fichier « cigale » a la plus petite taille en octets?
EXERCICE 6: compression d'un texte
Questions supplémentaires pour ceux en avance.
Lorsque l'on veut diminuer la taille d'un fichier texte, on utilise un algorithme de compression. Le codage de Huffman est une des techniques qui permet de diminuer le nombre de bits d'un texte selon le principe décrit dans le chapitre Ressources.
Le nombre binaire associé à chaque caractère est obtenu en parcourant l'arbre de la racine jusqu’à la feuille correspondant au caractère, en notant 0 une descente à gauche et 1 une descente à droite dans les branches de l'arbre.
On considère l'arbre ci-dessous, Le caractère R vaut 00 avec cet arbre:
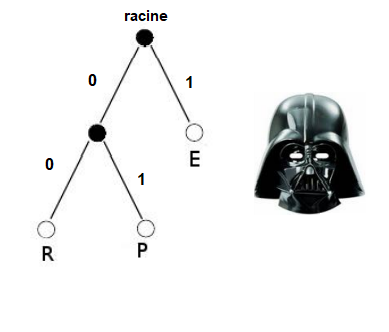
Questions 6.1
6.1.1 Donner le code binaire de P et E.
6.1.2 Donner le mot formé par le code : 011001 si on a utilisé cet arbre
Questions 6.2
On considère le mot "malayalam" et un arbre de Huffman associé:
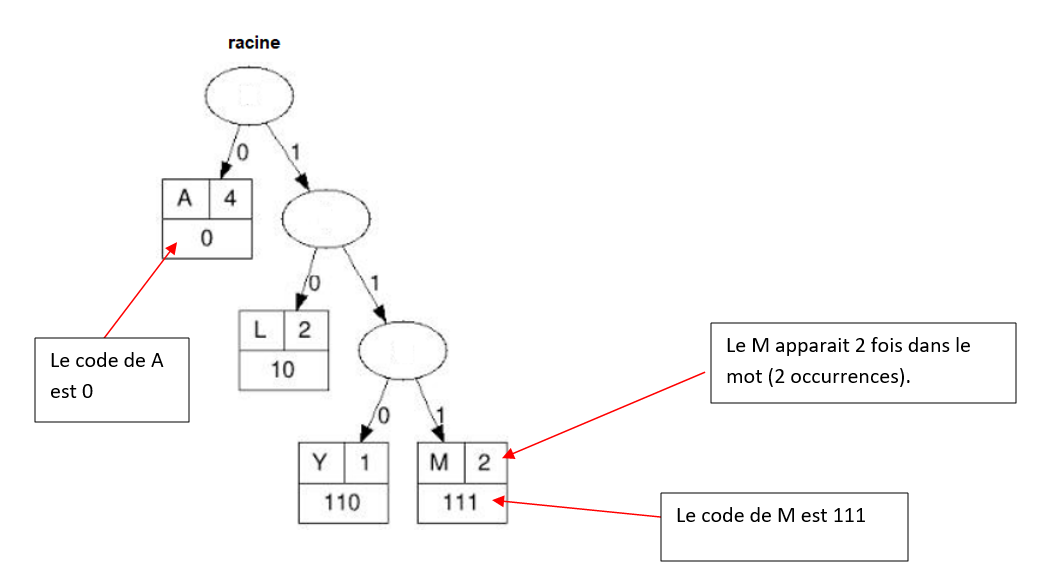
En supposant qu'avant le codage de Huffman, chaque caractère du mot malayalam était codé en ASCII sur 8 bits:
6.2.1 quelle était la taille du mot malayalam (en bits) ?
6.2.2 existe-t-il un « autre » arbre possible pour coder ce mot avec Huffman, expliquer pourquoi?
6.2.3 Quelle est la taille du mot s’il est codé avec un codage de Huffman ? Calculer ainsi le gain en % par rapport au codage ASCII.
Créé avec HelpNDoc Personal Edition: Documentation Qt Help facile