Ressources
- DHCP
Le service serveur DHCP appartient à la couche application ( voir le modèle en couches ci-dessous ou votre leçon), il a pour rôle d'affecter automatiquement une adresse IP à un client du réseau sur demande du service client DHCP qui appartient à la couche application du PC client. Quand une machine est démarrée, elle n'a aucune information de configuration réseau. Pour y parvenir, la technique utilisée est le broadcast : pour trouver et dialoguer avec un serveur DHCP, la machine va émettre un paquet dit de broadcast, ce paquet au niveau de sa couche Ethernet a pour destinataire l'adresse MAC FF:FF:FF:FF:FF ( qui signifie tous les hôtes du réseau), les données du protocole Ethernet encapsulent des données des couches supérieures dont celle du protocole IP, au niveau de la couche internet, le protocole IP demande à joindre l’hôte d'IP 255.255.255.255 (qui signifie tous les hôtes du réseau) , les données du protocole IP encapsulent les données du protocole de transmission UDP qui lui demande de communiquer les données qu'il encapsule à l'application qui écoute le port 67 ( le logiciel serveur DHCP) et de renvoyer la réponse à l'application qui écoute le port 68 le service client DHCP. Les données encapsulées dans le protocole UDP sont celles du protocole DHCP, elles contiennent au départ la requête "DHCPDISCOVER" ( je cherche un serveur DHCP) . Lorsque le serveur DHCP reçoit ce paquet de broadcast, il renvoie un autre paquet de broadcast contenant toutes les informations requises pour le client (n'oubliez pas que le client n'a pas encore d'adresse IP et n'est donc pas joignable directement);
Ainsi, le premier paquet émis par le client contient une requête " DHCPDISCOVER". Le serveur répond avec une requête "DHCPOFFER" pour proposer une adresse IP au client. Le client établit sa configuration, puis envoie une requête "DHCPREQUEST" pour valider son adresse IP. Le serveur répond par une requête DHCPACK avec l'adresse IP pour confirmation de l'attribution pour un bail en général de 30 jours.
Les diverses requêtes du protocole DHCP et leur signification:

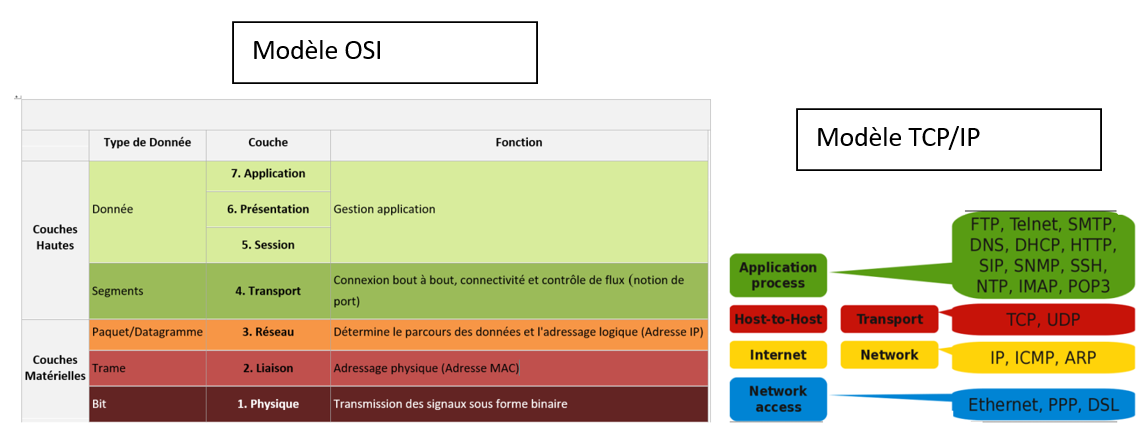
Que retenir de tout ça ? Vous n'avez pas à connaître tous les détails de la communication, il vous juste savoir que le principe est basée sur une communication en couches: les réseaux TCP/IP utilisent 4 couches qui encapsulent les données des autres couches. Pour l'attribution d'une adresse IP, le protocole DHCP de la couche application, le protocole UDP de la couche transmission, les protocoles IP et ARP de la couche internet et le protocole Ethernet de la couche réseau sont impliqués. Chaque couche traite les données de son protocole et transmet le reste des données à la couche inférieure ( lors de l'envoi) ou à la couche supérieure ( lors de la réception). Vous aurez l'occasion dans ce TP d'analyser à quoi ressemblent les données de ces protocoles.
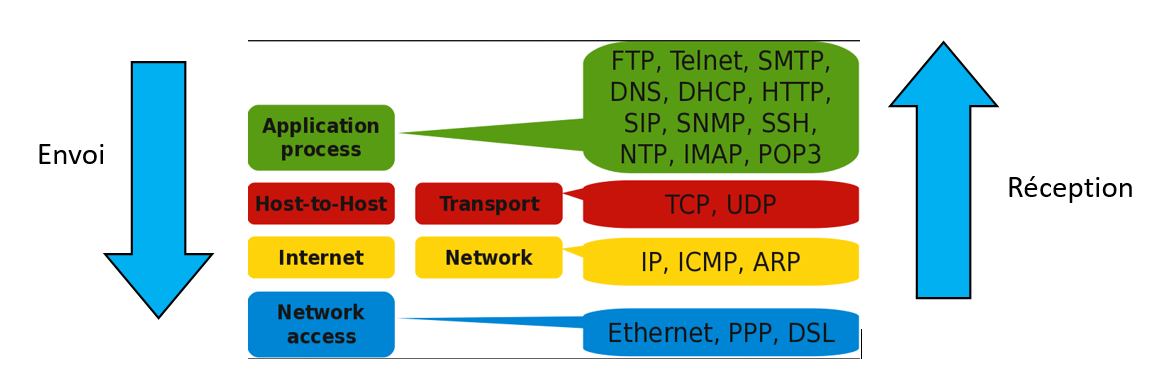
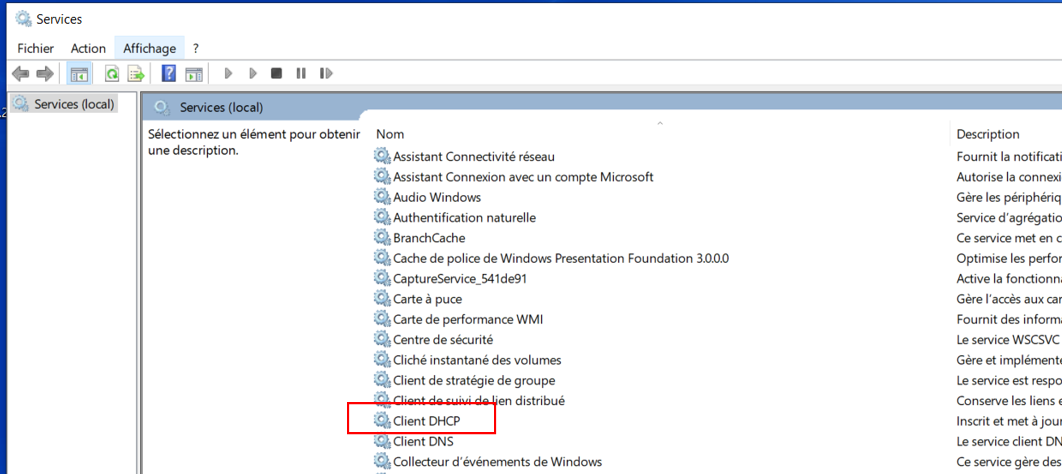
Ci-dessous les divers services d'une machine cliente sous Windows 10, le service client DHCP est entouré en rouge:
- DNS
Comment ça marche: la résolution de noms est le processus qui consiste à associer des noms de machines et des adresses IP. Les machines (appelées « hôtes » ) d'un réseau TCP/IP ont plusieurs identités. Les équipements du réseau utilisent ces identités pour fournir les données aux bons hôtes.
Les trois identités sont :
- L'adresse MAC (Media Access Control) correspond à un numéro encodé dans la carte réseau.
- L’adresse IP est attribuée par logiciel à la carte interface réseau.
- Le nom d'hôte (hostname) est le nom d’une machine, il a été défini lors de l'installation du système d'exploitation, il est notamment utilisé par les systèmes d'exploitation.
Ces différentes identités permettent de trouver une machine sur un réseau. Parce que les identités diffèrent, il existe des protocoles pour les relier les unes aux autres. Par exemple, le protocole ARP (Address Resolution Protocol) relie les adresses MAC aux adresses IP . Le protocole DNS ( Domain Name System) relie les noms d'hôtes et les adresses IP.
Pour associer le nom et l'IP l'OS utilise deux méthodes, un fichier local qui est lu en premier et un serveur de données DNS pour résoudre les noms d'hôtes qui ne sont pas dans le fichier local. La première méthode repose sur un fichier texte nommé hosts qui se trouve sur le disque dur de la machine locale. Le fichier hosts est pertinent pour une utilisation occasionnelle, mais il est difficile de le tenir à jour. Chaque fois que le nom d'hôte ou l'adresse IP d'une machine changerait, le fichier hosts devrait être mis à jour sur toutes les autres machines du réseau, cette méthode serait trop lourde.
La seconde méthode consiste à stocker tous les noms et adresses IP sur un (ou plusieurs) serveur appelé serveur DNS et à configurer les hôtes pour qu'ils interrogent ce serveur. Les serveurs DNS maintiennent une base de données de noms et d'adresses IP. Les systèmes d'exploitation des clients, tels que Windows, Linux et macOS, mettent dynamiquement à jour la base de données du serveur DNS chaque fois que leur nom d'hôte ou leur adresse IP change. Lorsqu'un utilisateur saisit un nom d'hôte dans le cadre d'une commande, telle que ping Serveur, le système interroge le serveur DNS pour obtenir l'adresse IP de Serveur.
Les systèmes d'exploitation incluent un service client DNS qui vérifie le fichier hosts et interroge la base de données DNS quand nécessaire.
Le client et le serveur DNS communiquent sur le réseau en utilisant le port 53. Les clients utilisent le protocole UDP port 53 pour s'adresser aux serveurs et les serveurs utilisent le protocole TCP sur le port 53 pour les transferts d'informations entre serveurs DNS. Les transferts d'informations permettent aux serveurs DNS de se mettre à jour les uns les autres.
Les clients d'un réseau qui demandent des ressources internes à ce réseau utilisent des serveurs DNS internes, c'est ce que vous allez configurer sur Filius.
Sur notre filius, la machine d'IP 192.168.0.1 sera l'hostname Serveur
Si la ressource est externe ( sur internet) , le client DNS va interroger des serveurs DNS externes et là c'est plus compliqué. Les noms Internet sont organisés hiérarchiquement en domaines, en commençant par la racine - représentée par un seul point - suivie par les domaines de premier niveau, tels que fr, edu, org, etc. Les demandes de résolution de noms passent d'une couche à l'autre jusqu'à ce que le nom soit résolu. Les URL sont les chemins d'accès. Par exemple, le nom fr.wikipedia.org se lit : « aller à domaine org, trouver le domaine wikipedia, puis trouver le domaine fr. ».
Exemple de résolution de noms pour fr.wikipedia.org, chaque domaine a un ou plusieurs serveurs DNS qui le représente:
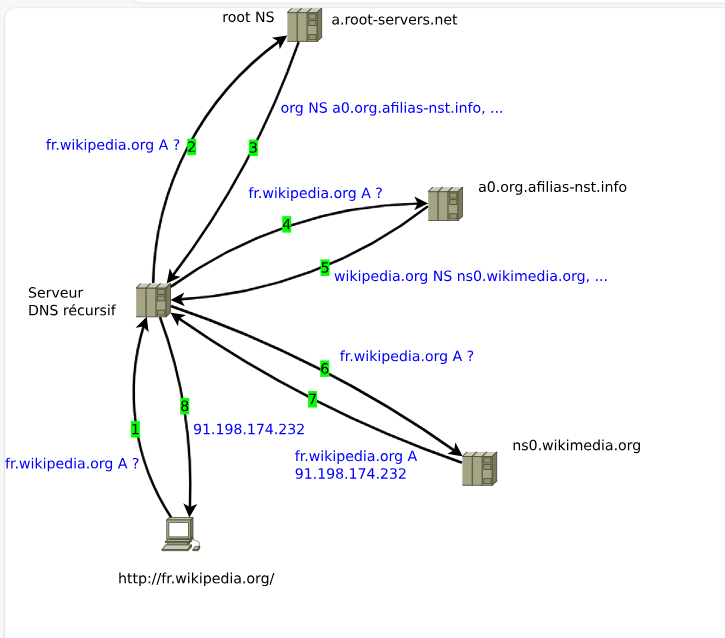
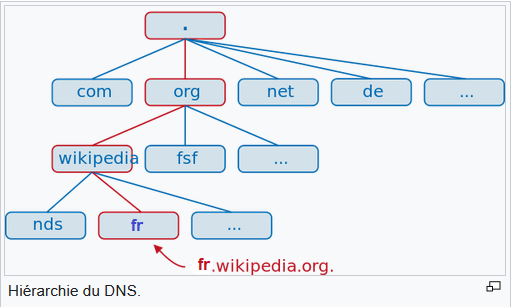
- Protocole ARP (Address Resolution Protocol)
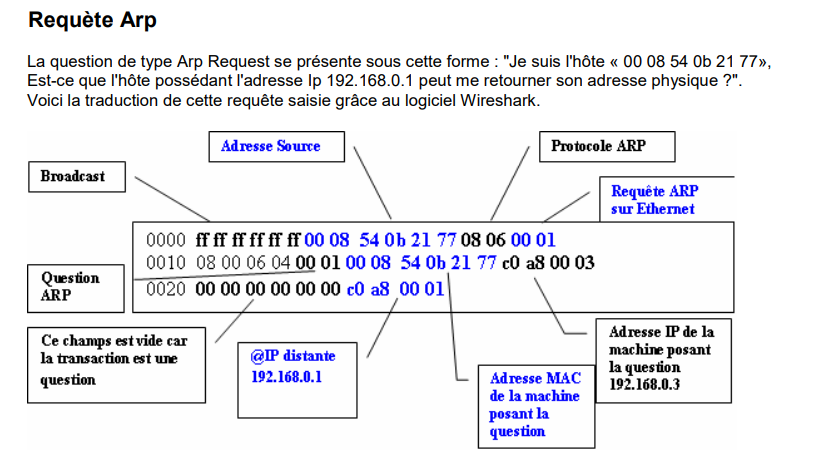
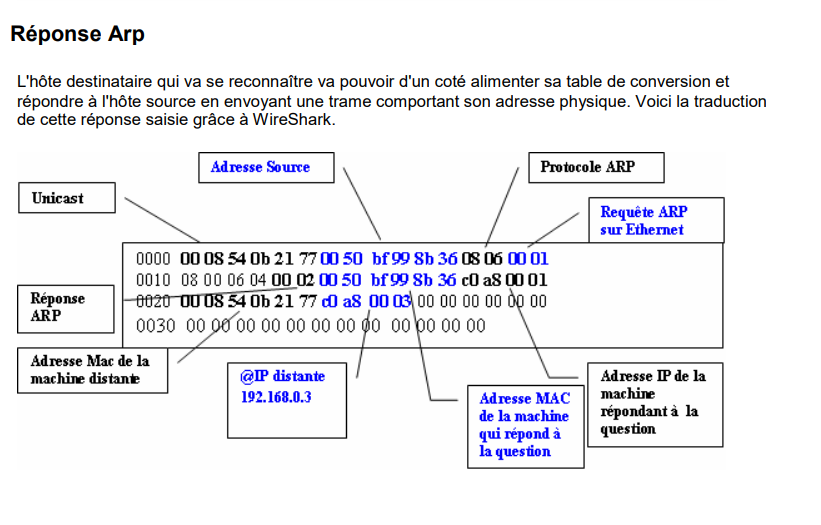
Le protocole ARP a pour rôle d'établir la correspondance entre l'adresse physique ( adresse MAC) et l'adresse IP d'un hôte. Il établit une table appelée table ARP qui contient l'adresse IP et MAC de tous les hôtes qu'il connaît.
Si les deux hôtes n'ont jamais discuté ensemble la table ARP est vide. La machine source ne connaissant pas l'adresse physique de la machine destinatrice, elle doit émettre une trame Broadcast s'adressant à toutes les hôtes du réseau, comportant sa propre adresse physique et la question demandée. Puis, l'hôte de destination va se reconnaître et répondre en unicast ( au demandeur uniquement).
Message ARP:

Le champ opération permet de connaître la fonction du message et donc son objectif.
Voici les différentes valeurs possibles.
- 01 - Request [RFC 826]
- 02 - Reply [RFC 826]
Tous les détails du protocole ARP ici
- Protocole ICMP
Le protocole ICMP (Internet Control Message Protocol) signale des erreurs au niveau IP. Le type de message "Demande d'ECHO " est notamment utilisé par le programme ping pour tester la connectivité entre deux hôtes . Ping demande au protocole ICMP (côté émetteur) d'envoyer un message ICMP de type 8 code 0 , ICMP (côté émetteur) attend en réponse un message du protocole ICMP (côté destinataire) de type 0 code 0 . Au bout d'un certains délai, si le destinataire ne répond pas le protocole ICMP (côté émetteur) émet un message de type 3 type 1 qui signifie que l'hôte n'est pas accessible. Ping va redemander plusieurs fois l'échange pour s'assurer de la (non)disponibilité du destinataire.


- Protocole de contrôles de transmission des réseaux TCP/IP: UDP et TCP
Lors d'une communication client-serveur sur un réseau TCP/IP, les données sont découpées en petits paquets appelés segments de données, chaque segment est numéroté puis encapsulé dans un paquet IP (paquet d’octets compréhensible par le protocole IP) qui contient l’adresse IP du destinataire et celle de l’envoyeur; éventuellement en fonction du trafic réseau, chaque segment va emprunter une route différente et les segments vont se perdre ou arriver dans le désordre. Le rôle du protocole de contrôle de transmission est la reconstitution des segments et la remise de l’information reconstituée à l’application concernée.
Il existe deux protocoles de contrôle de transmission appelés UDP et TCP qui interviennent au niveau la couche transport du modèle TCP/IP ( au niveau de la couche 4 du modèle théorique OSI).
UDP (User Datagram Protocol ): ce protocole permet la transmission sans vérification que tous les paquets ont bien été reçus, UDP est utilisé pour des communications peu critiques. Plusieurs applications (logiciels) d’une même machine peuvent communiquer par le réseau au même moment, pour identifier l’application destinataire, le protocole UDP utilise un identifiant appelé port. Un port est juste un numéro qui identifie le logiciel qui envoie les données ou le logiciel qui doit les recevoir; un segment contient le port de communication de l’envoyeur qui identifie l’application sur la machine source (un navigateur web qui demande une page web par exemple) et le port de communication de l’application destinataire (le serveur web à qui s’adresse la demande par exemple).
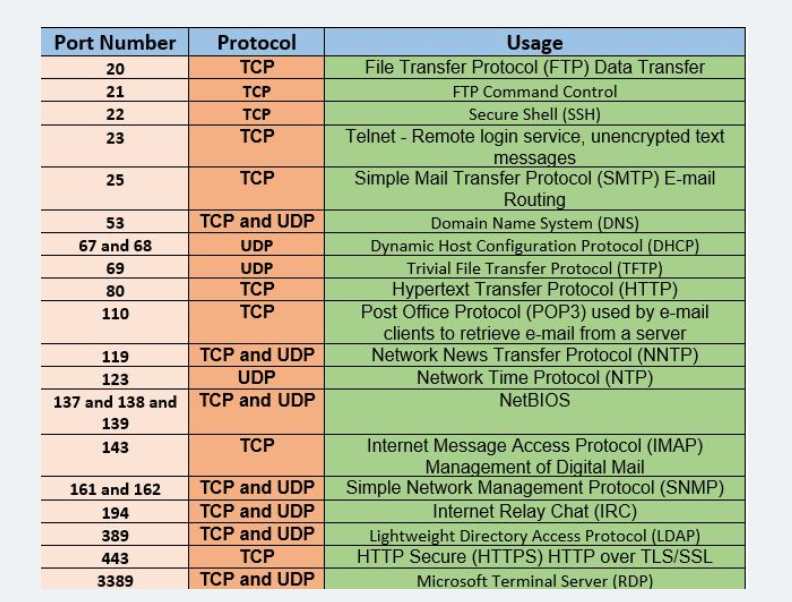
Certains ports sont réservés à des services réseaux clairement identifiés. Par exemple le port 80 est réservé pour le protocole http des échanges web.
TCP ( transmission control protocol) : TCP est un protocole orienté connexion, c'est-à-dire qu'il permet à deux machines qui communiquent de contrôler l'état de la transmission. Les applications peuvent communiquer de façon sûre (grâce à un système d'accusé de réception), comme UDP, TCP utilise des segments (des petits paquets) et les mêmes ports qu’UDP pour identifier les applications.
Exemple de transmission avec accusé de réception :
Le client choisit aléatoirement un numéro (1234 dans l’exemple ci-dessous) et envoie un paquet TCP étiqueté SYN ( synchronized) avec le numéro 1234. Le serveur se choisit aussi un nombre aléatoirement (301 dans l’exemple) puis répond au client qu'il veut bien communiquer avec un paquet étiqueté (SYN-ACK : synchronized acknowledgement), le paquet SYN-ACK contient le numéro du client incrémenté de 1 soit 1235 et son propre numéro ( 301) , sur réception de ce paquet le client considère sa connexion établie. Le client renvoie un paquet ACK avec son numéro et celui du client incrémenté (1235, 202) , sur réception de ce paquet le serveur se considère comme connecté.
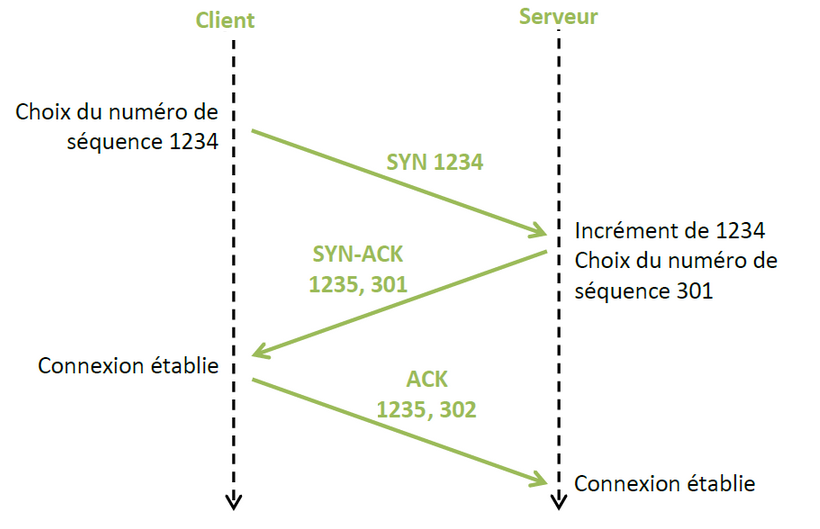
figure 1
Le client et le serveur peuvent alors s'envoyer les paquets de données en poursuivant la numérotation (incrémentation du numéro de séquence).
- Protocole du bit alterné
Nous avons vu que le protocole TCP propose un mécanisme d'accusé de réception afin de s'assurer qu'un paquet est bien arrivé à destination. Le processus d'acquittement permet de détecter les pertes de paquets au sein d'un réseau, l'idée étant qu'en cas de perte, l'émetteur du paquet renvoie le paquet perdu au destinataire. Nous allons ici étudier un protocole simple de récupération de perte de paquet : le protocole de bit alterné.
Le protocole de bit alterné est implémenté au niveau de la couche accès réseau du modèle TCP/IP ( la couche n° 2 dite de "liaison de données" du modèle théorique OSI ), il ne concerne donc pas les paquets IP, mais les trames échangées par l'électronique (on parle de paquets uniquement à partir de la couche internet du modèle TCP/IP (couche 3 "Réseau" du modèle théorique OSI).
Le principe de ce protocole est simple, considérons 2 ordinateurs en réseau : un ordinateur A qui sera l'émetteur des trames et un ordinateur B qui sera le destinataire des trames. Au moment d'émettre une trame, A va ajouter à cette trame un bit (1 ou 0) appelé drapeau (flag en anglais). B va envoyer un accusé de réception (acknowledge en anglais souvent noté ACK) à destination de A dès qu'il a reçu une trame en provenance de A. À cet accusé de réception on associe aussi un bit drapeau (1 ou 0).
La règle est relativement simple : la première trame envoyée par A aura pour drapeau 0, dès cette trame reçue par B, ce dernier va envoyer un accusé de réception avec le drapeau 1 (ce 1 signifie "la prochaine trame que A va m'envoyer devra avoir son drapeau à 1").
Dès que A reçoit l'accusé de réception avec le drapeau à 1, il envoie la 2e trame avec un drapeau à 1, et ainsi de suite...
Le système de drapeau est complété avec un système d'horloge côté émetteur. Un "chronomètre" est déclenché à chaque envoi de trame, si au bout d'un certain temps, l'émetteur n'a pas reçu un acquittement correct (avec le bon drapeau), la trame précédemment envoyée par l'émetteur est considérée comme perdue et est de nouveau envoyée.
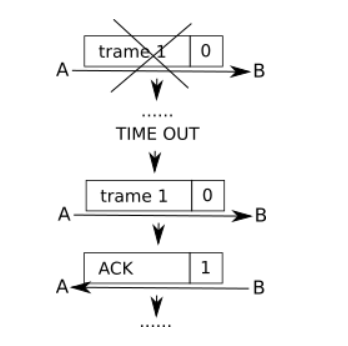
Examinons quelques cas :
La trame est perdue, au bout d'un certain temps ("TIME OUT"), A n'a pas reçu d'accusé de réception, la trame est considérée comme perdue, elle est donc renvoyée.
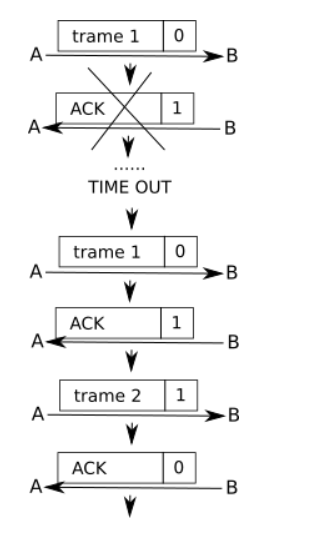
L'accusé de réception est perdu, A ne reçoit pas d'accusé de réception avec le drapeau à 1, il renvoie donc la trame 1 avec le drapeau 0. B reçoit donc cette trame avec un drapeau à 0 alors qu'il attend une trame avec un drapeau à 1 (puisqu'il a envoyé un accusé de réception avec un drapeau 1), il "en déduit" que l'accusé de réception précédent n'est pas arrivé à destination : il ne tient pas compte de la trame reçue et renvoie l'accusé de réception avec le drapeau à 1. Ensuite, le processus peut se poursuivre normalement.
Créé avec HelpNDoc Personal Edition: Créer des documents d'aide HTML facilement